Preparation¶
In this example, we prepare training/validation data for melody/vocal separation task.
Before running bunch of codes below, please download DSD100 dataset from the DSD100 download page and say it DSD100.zip.
Initialize Sampler for train¶
[1]:
from chimeranet.datasets import DSD100Melody, DSD100Vocal
from chimeranet import DatasetSampler, SyncSampler
dsd100_path = 'DSD100.zip'
duration = 2.
sr = 16000
# Dataset
vocal_dataset = DSD100Vocal(dsd100_path, dev=True, test=False)
# Sampler
vocal_sampler = DatasetSampler(vocal_dataset)
# augmentation
vocal_sampler.amplitude_factor = (-0.5, 0.5)
vocal_sampler.stretch_factor = (-0.1, 0.1)
vocal_sampler.shift_factor = (-0.1, 0.1)
# do same things to melody channel
melody_dataset = DSD100Melody(dsd100_path, dev=True, test=False)
melody_sampler = DatasetSampler(melody_dataset)
melody_sampler.amplitude_factor = (-0.5, 0.5)
melody_sampler.stretch_factor = (-0.1, 0.1)
melody_sampler.shift_factor = (-0.1, 0.1)
# combine two channels together
sampler = SyncSampler(vocal_sampler, melody_sampler)
sampler.duration = duration
sampler.samplerate = sr
Sample audio and make train data¶
[2]:
import librosa
from chimeranet import to_training_data
n_fft = 512
hop_length = 128
n_mels = 150
sample_size = 32
T = librosa.time_to_frames(duration, sr, hop_length, n_fft)
F = n_mels
samples = sampler.sample(sample_size, n_jobs=4)
x_train, y_train = to_training_data(
samples, T, F, sr=sr, n_fft=n_fft, hop_length=hop_length, n_jobs=4,
)
Save train data¶
[3]:
import h5py
with h5py.File('example-dataset-train.hdf5', 'w') as f:
f.create_dataset('x', data=x_train)
f.create_dataset('y/mask', data=y_train['mask'])
f.create_dataset('y/embedding', data=y_train['embedding'])
Show one of the training data¶
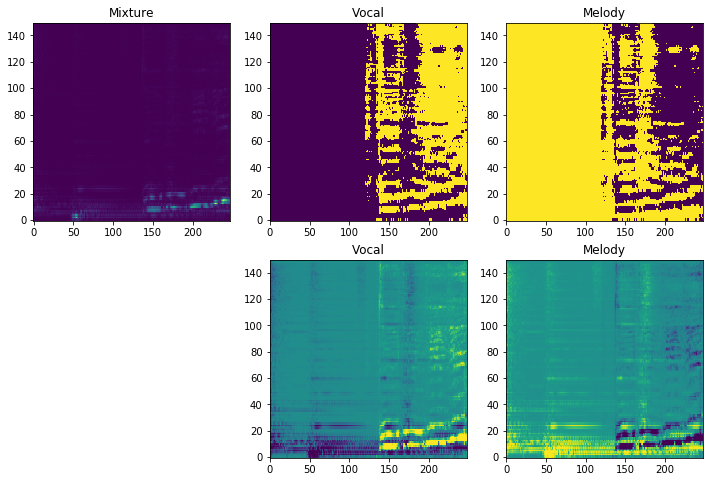
[4]:
%matplotlib inline
import matplotlib.pyplot as plt
idx = 0
mixture = x_train[idx].transpose((1, 0))
mask_e = y_train['embedding'][idx].transpose((2, 1, 0))
mask_m = y_train['mask'][idx].transpose((2, 1, 0))
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(2, 3, 1)
ax.title.set_text('Mixture')
ax.imshow(mixture, origin='lower', aspect='auto')
for i, (mask, name) in enumerate(zip(mask_e, ('Vocal', 'Melody')), 1):
ax = fig.add_subplot(2, 3, 1+i)
ax.title.set_text(name)
ax.imshow(mask, origin='lower', aspect='auto', vmin=0, vmax=1)
for i, (mask, name) in enumerate(zip(mask_m, ('Vocal', 'Melody')), 1):
ax = fig.add_subplot(2, 3, 4+i)
ax.title.set_text(name)
ax.imshow(mask, origin='lower', aspect='auto', vmin=0, vmax=1)
Validation data¶
Like training data, validation data can be made in almost same way.
[5]:
# vocal channel
vocal_dataset = DSD100Vocal(dsd100_path, dev=False, test=True)
vocal_sampler = DatasetSampler(vocal_dataset)
vocal_sampler.amplitude_factor = (-0.5, 0.5)
vocal_sampler.stretch_factor = (-0.1, 0.1)
vocal_sampler.shift_factor = (-0.1, 0.1)
# melody channel
melody_dataset = DSD100Melody(dsd100_path, dev=False, test=True)
melody_sampler = DatasetSampler(melody_dataset)
melody_sampler.amplitude_factor = (-0.5, 0.5)
melody_sampler.stretch_factor = (-0.1, 0.1)
melody_sampler.shift_factor = (-0.1, 0.1)
# combine two channels together
sampler = SyncSampler(vocal_sampler, melody_sampler)
sampler.duration = duration
sampler.samplerate = sr
# make validation data
samples = sampler.sample(sample_size, n_jobs=4)
x_validation, y_validation = to_training_data(
samples, T, F, sr=sr, n_fft=n_fft, hop_length=hop_length, n_jobs=4,
)
# save validation data
with h5py.File('example-dataset-validation.hdf5', 'w') as f:
f.create_dataset('x', data=x_train)
f.create_dataset('y/mask', data=y_validation['mask'])
f.create_dataset('y/embedding', data=y_validation['embedding'])
[1] A. Liutkus et al., “The 2016 Signal Separation Evaluation Campaign,” in Latent Variable Analysis and Signal Separation - 12th International Conference, {LVA/ICA} 2015, Liberec, Czech Republic, August 25-28, 2015, Proceedings, 2017, pp. 323–332.